To exclude coarse sieves from the regression, make use of a) a conditional array which excludes coarse sieves with a cumulative % retained of zero or lower than a selectable value b) a workbook with different worksheets for different number of sieves c) editing of the regression formula via F2.
The diagram illustrates the M.A. (50%) and the range of variation (50±34 %) in red, the values for the 7 sieves in blue and the regression curve:
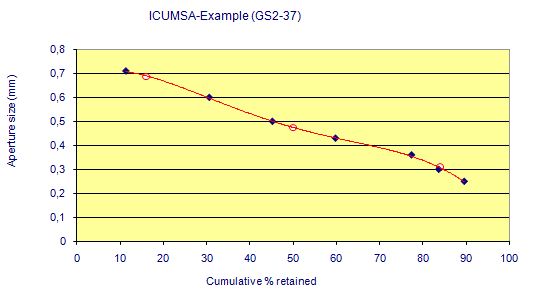
The M.A. result of the Powers method in the ICUMSA example is 0.49 mm, which differs from the polynomial result (0.47 mm). But from figure 1 in the method description of "GS2-37" it is evident that two points near 50 % are outside the straight line.
What would happen with the Powers method, if a sieve will show - by pure chance - a cumulative weight of 50.00 %, which is M.A. per definition ?
Analysts could draw a line away from this important sieve (point) and could state another value of M.A. from the regression line. The same could happen with other linear regression models.
But the polynomial evaluation will indeed show an M.A. close to the sieve which had - by pure chance - 50.00 % of cumulative weight.
According to a discussion with G. Pezzi, the base pan should be included to the polynomial regression.